Design priors, compose architectures, train, test, share — one place to build a foundation model for your domain. No data-generation code to write. No infra to glue.
Reference study: PFN within 1.23× of OLS on held-out tasks, trained in ~47s on CPU. See the study →
Built on the prior-fitted networks architecture introduced in Müller et al., ICLR 2022. A prior is just Python code that generates synthetic training data — train on it once, get a model that does in-context inference on any real dataset of the same shape.
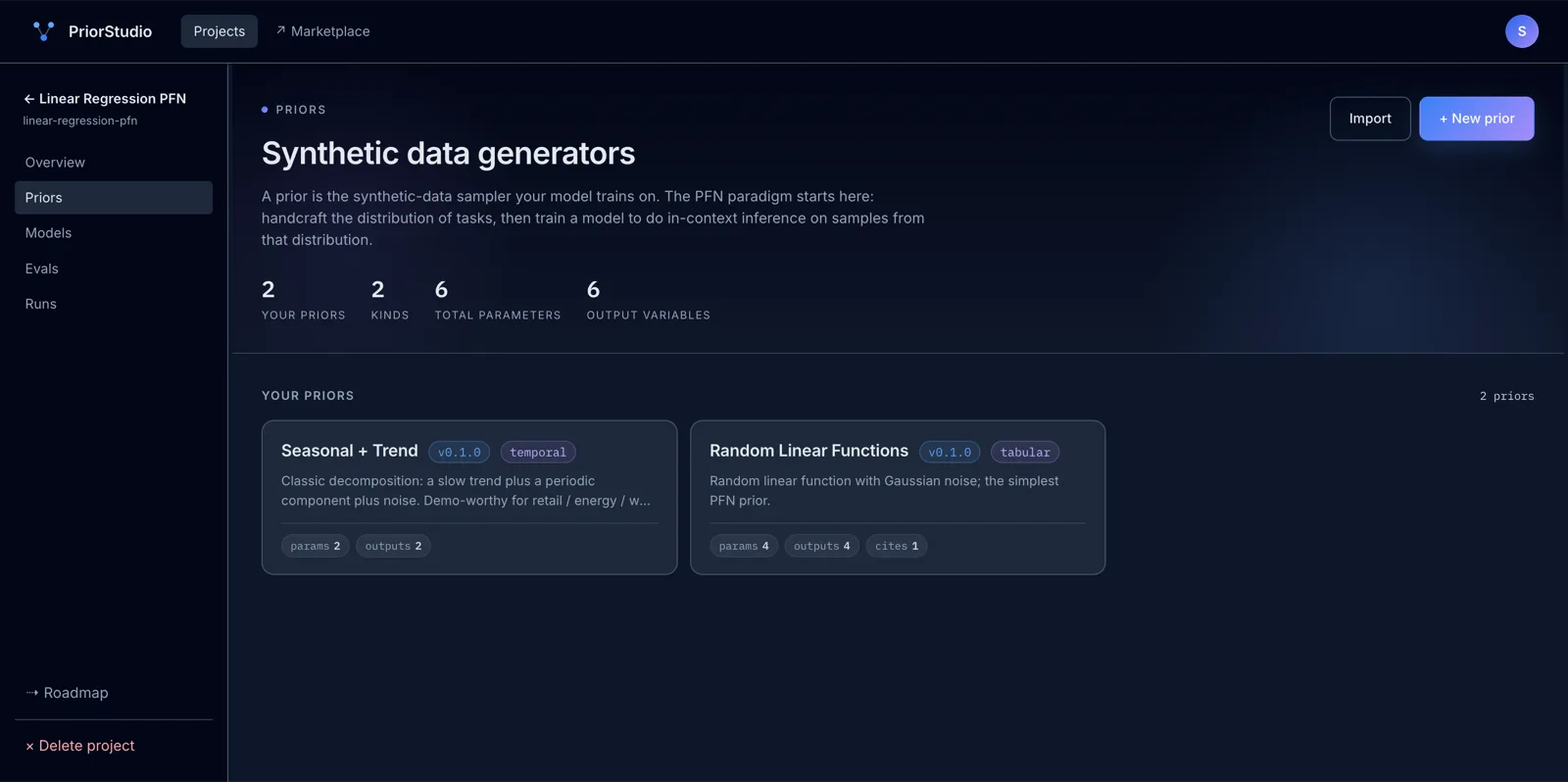
Project overview — prior · model · eval · run
Build models that
Forecast time series
sensor · demand · traffic
Classify tabular data
churn · fraud · risk
Discover causal structure
process · root cause
Bayesian inference
in-context posteriors
Made for
Whoever's closest to the prior.
ML engineers
Stop hand-rolling training loops and eval harnesses for every domain. Author once, the studio runs everything.
Data scientists
Get a working in-context model on your problem in minutes — fast enough to make it a prototyping tool, not a quarter-long project.
Domain experts
You know the physics or the data better than any ML team. Start from a prior that matches your domain — no PyTorch required.
Quick answers
The three things people ask first.
What's a foundation model? How is this different from GPT?
Both are foundation models — trained on a lot of data, reused as the base for many downstream tasks. GPT learned from internet text and writes code and prose. A prior-fitted network learns from synthetic priors you (or the community) author, and does in-context inference on tabular, time-series, or causal data — without fine-tuning. Same paradigm, different substrate.
Who is ProfitOps? Why is this from them?
ProfitOps is an industrial AI company. We build causal foundation models for continuous-process manufacturing — pulp and paper, chemicals, and adjacent verticals. To ship at our customers' pace we built a studio for authoring priors, composing architectures, training, and sharing models. PFN Studio is that internal studio, opened up — the same one our team uses on production deployments.
How is this different from Hugging Face?
Hugging Face hosts pre-trained models built by other people. PFN Studio is where you author the prior, train your own foundation model on it, and deploy. Different layer of the stack — HF gives you finished cake; we give you the oven.
TCPFN is the in-house PFN that powers ProfitOps' digital-workforce platform. One temporal model, three jobs: causal discovery, treatment-effect estimation, and root-cause analysis on continuous-process data. We built the studio because we needed it to build TCPFN; we opened it up because the next domain-specific PFN is yours.
Everything you need to take a foundation model from idea to a trained, shareable artifact — and nothing you don't.
01
★Ready
Marketplace
Start from a curated library of priors.
13 ready-to-train priors plus 6 model templates and 9 OSS PFN projects. Fork any of them into your workspace.
Click to expand →
02
★Ready
Runner
Train in the cloud, no setup.
Click Run and watch the loss curve update live in your browser — training happens on our infrastructure. CPU included during early access; GPU on demand as you scale.
Click to expand →
03
★Ready
Share
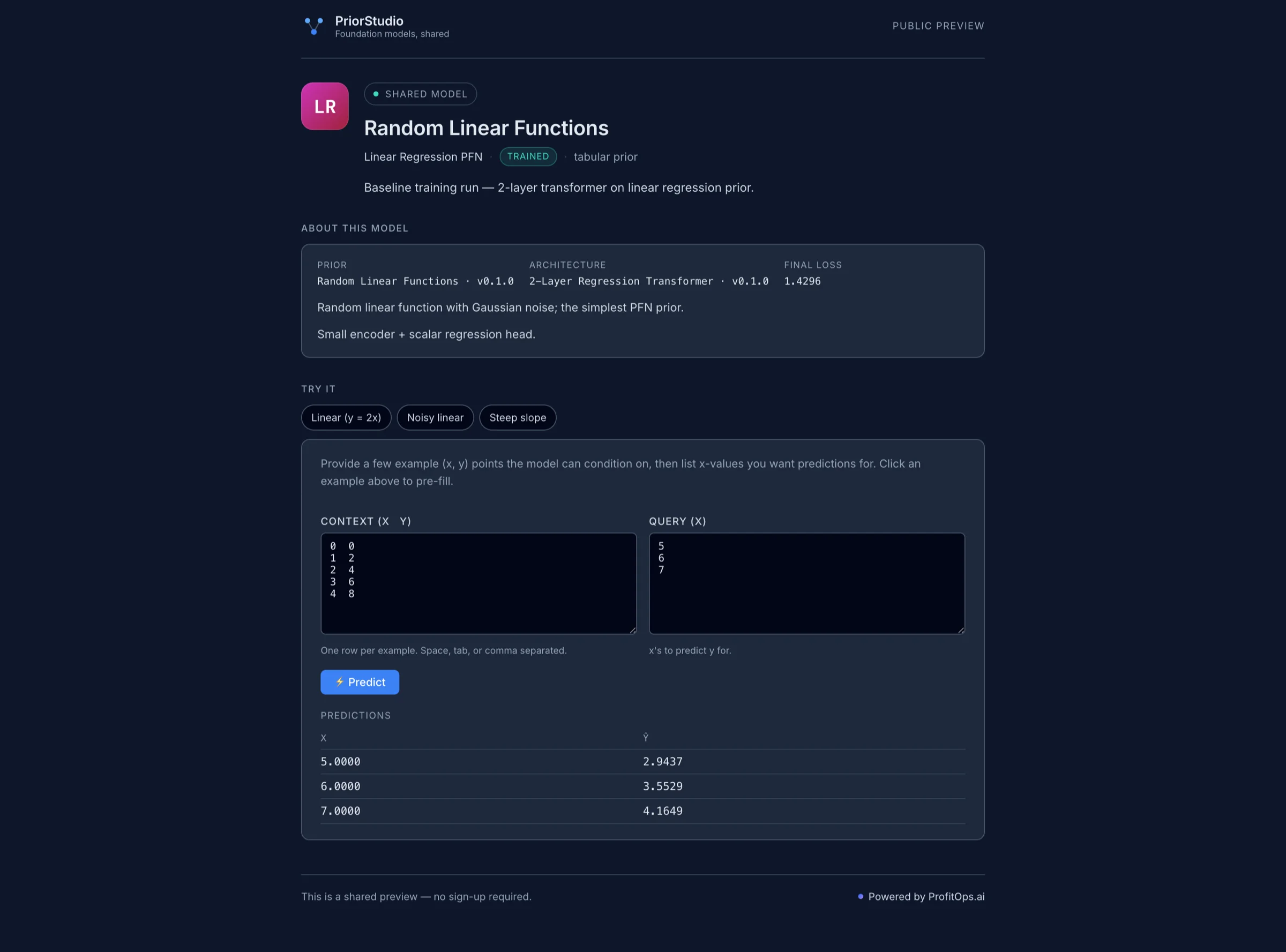
Public Try-it links per trained model.
Generate a public URL for any completed run. Recipients open a Try-it page, paste their data, get predictions — no sign-up required.
Click to expand →
04
◐Beta
Designer
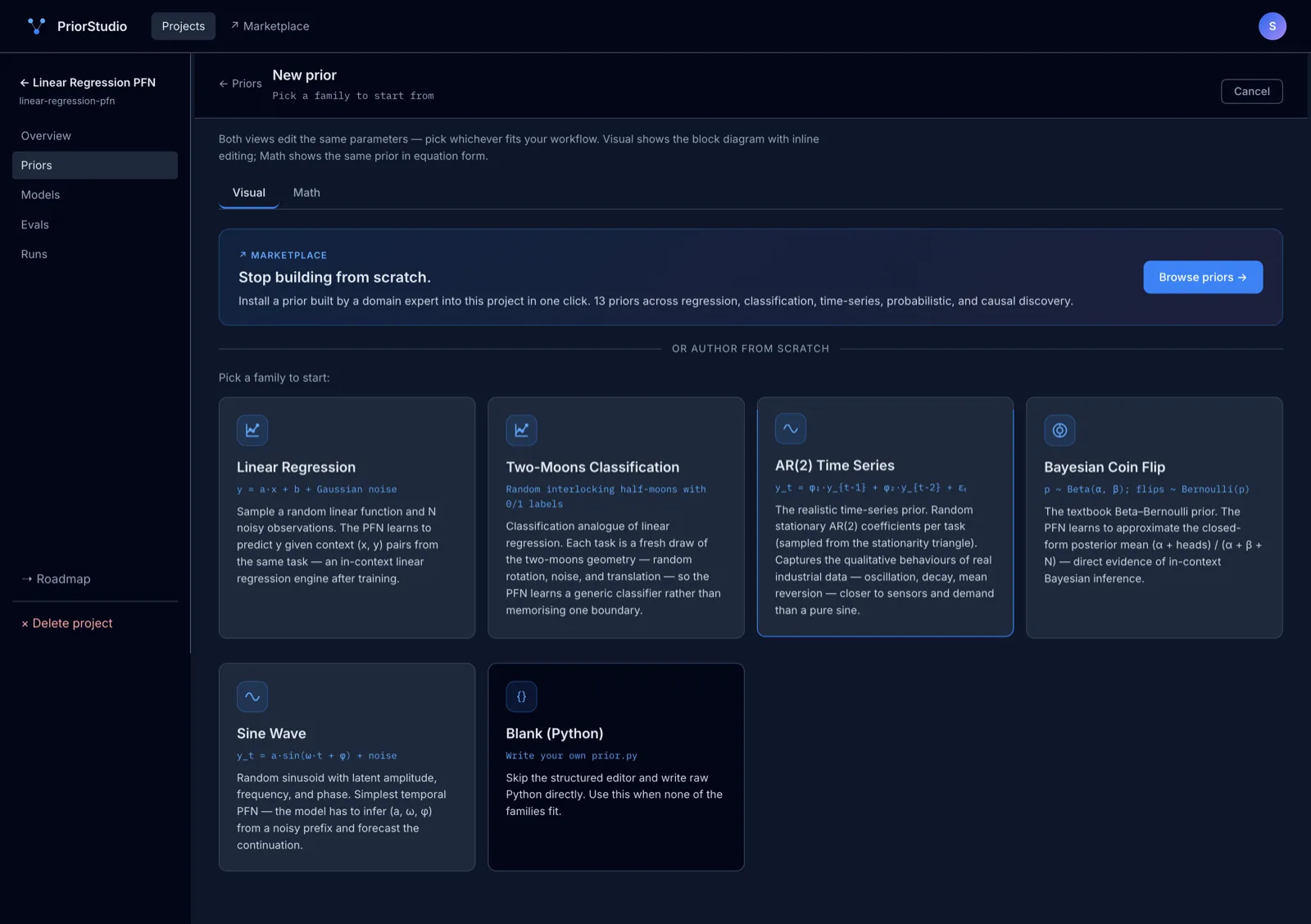
Author priors visually, in math, or in Python.
Block-diagram editor for the visual mode. Equation-form editor for the math mode. Raw prior.py for full control. Five built-in families to start from.
Click to expand →
05
◐Beta
Composer
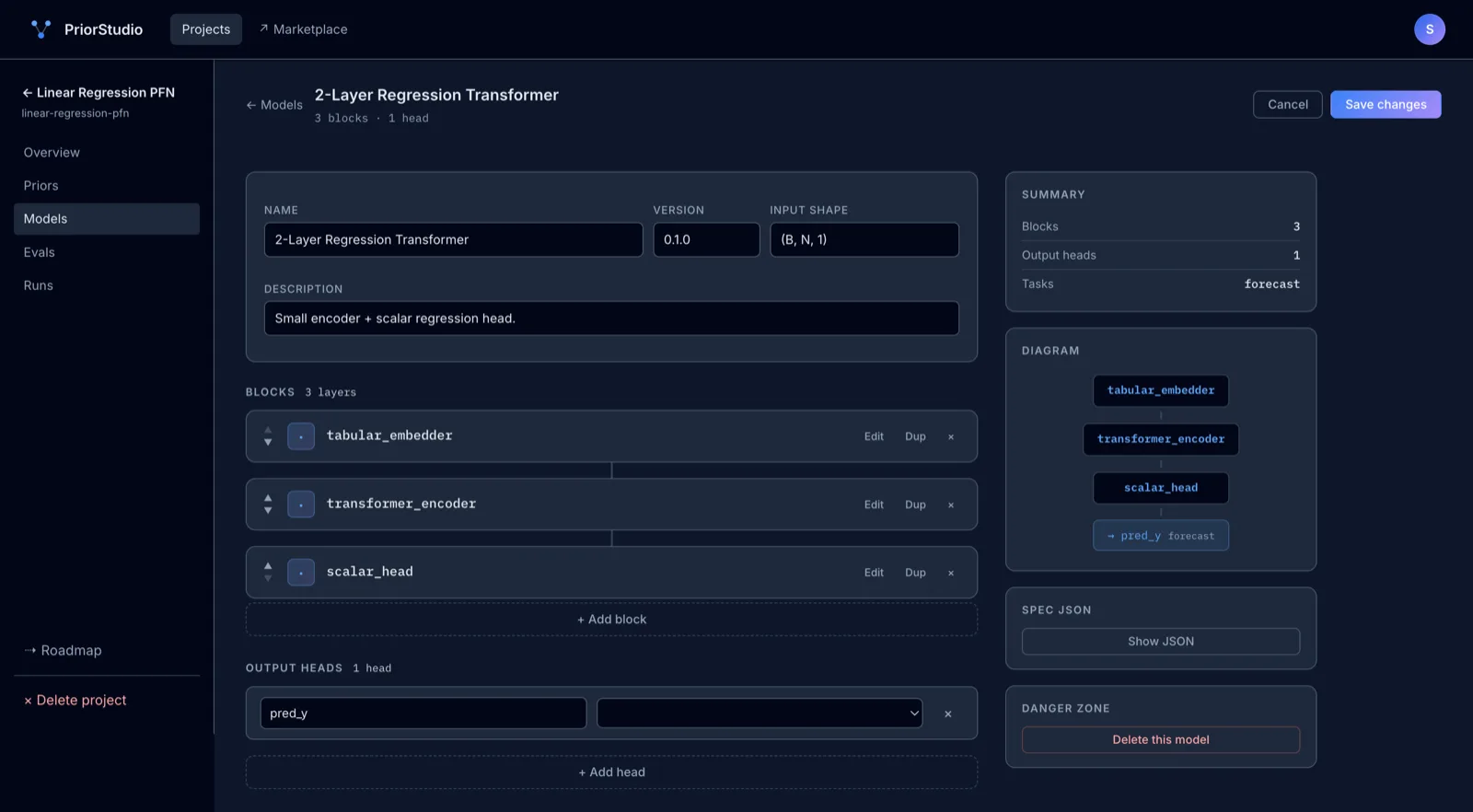
Compose architectures from blocks.
Drag tabular embedders, transformer encoders, attention pools, and task heads into a model spec. Add your own blocks with a single decorator.
Click to expand →
From the marketplace
Start from a prior. Train. Done.
Every prior is a Python file plus a parameter spec — built by the community, validated against a baseline, ready to fork into your project.
Install from the marketplace, fork an existing one, or design your own in the visual editor. A prior is just Python that generates synthetic data the model can train on.
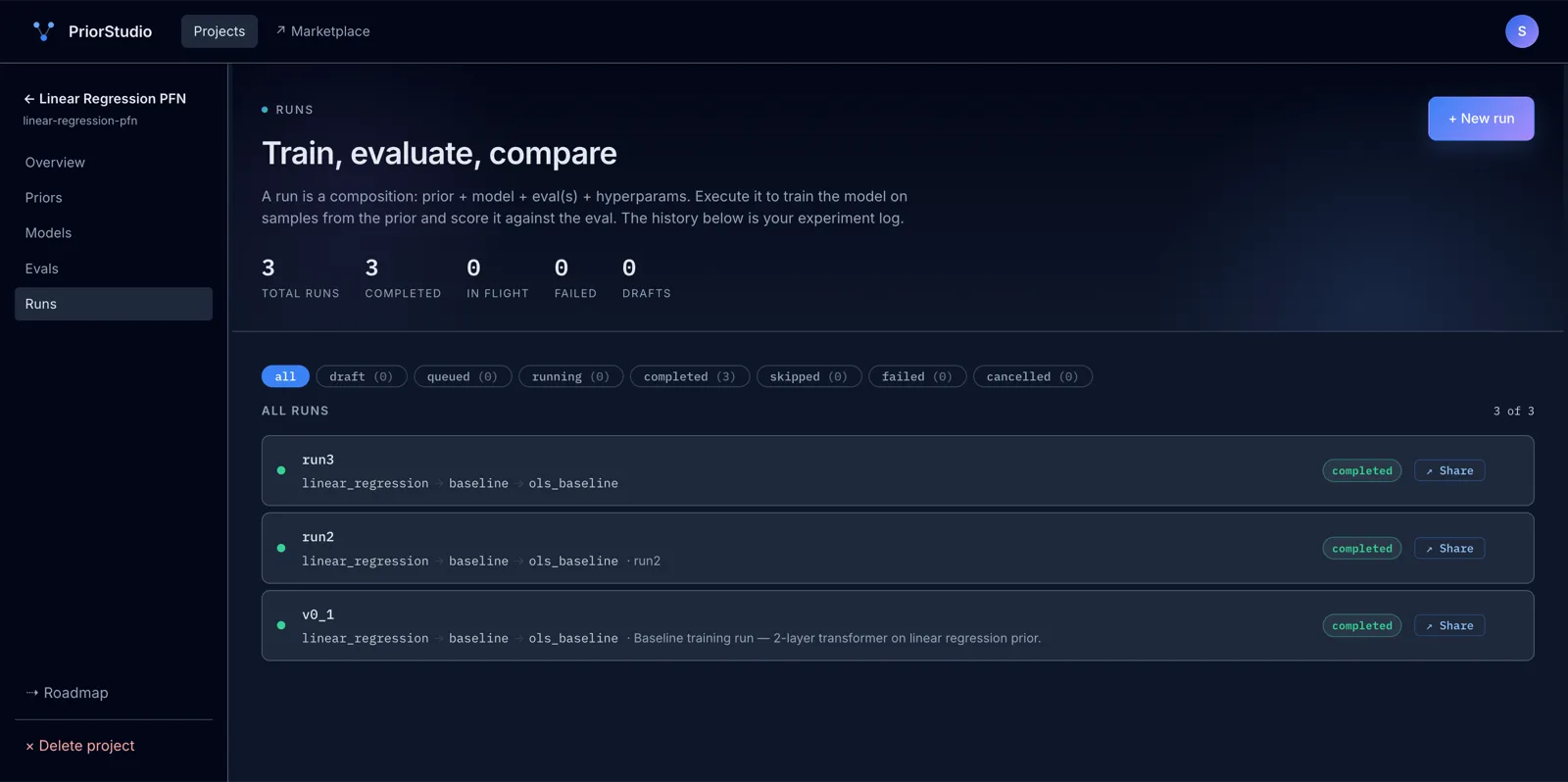
2
Train
Hit ▶ Run. We spin up the training job on our infrastructure. You watch the loss curve update live, inspect every step, and fail loudly with structured error logs if something's off.
3
Test and share
Try predictions in the in-product widget. Generate a public link, send it to a customer or colleague — they paste their data and see predictions without an account.
How is this different
Traditional ML stack vs. PFN Studio.
Most teams ship a foundation model by gluing six tools and writing a lot of YAML. PFN Studio collapses the stack so you spend time on the prior, not the infra.
Traditional ML stack
PFN Studio
✕Months of data labeling per model
✓Trains on synthetic priors — no labels needed
✕Hand-rolled training loop per project
✓The studio runs the loop
✕Fine-tune a Hugging Face checkpoint
✓Train a model that does in-context inference
✕Hand-built UI to show stakeholders
✓One-click public Try-it links per model
✕GPU bills before you have a prototype
✓Free during early access · GPU on demand later
What your customer sees
A public Try-it link — no sign-up, no account, just paste data and get predictions.
Common questions
The long-tail questions.
Short answers to the questions that come up most. Reach out at hello@profitops.ai if yours isn't here.
What's a foundation model? How is this different from GPT or Claude?
A foundation model is any model trained on a lot of data and then reused as the base for many downstream tasks. GPT and Claude are foundation models for language — they learned from internet-scale text and can write, summarise, and code. PFN Studio is for foundation models in your domain: tabular data, time series, causal structure. They don't read text; they read your data and do in-context inference (forecast, classify, discover structure) without fine-tuning. Same paradigm, different substrate — GPT trained on the web, PFN-style models train on synthetic priors you (or the community) author.
What's a prior, in plain English?
A `prior.py` file that returns synthetic training samples — random linear functions, random AR(2) time series, random Bayesian outcomes, whatever fits your domain. Fork one from the marketplace or write your own in the Designer.
Who is ProfitOps? Why is this from them?
ProfitOps is an industrial AI company. We build causal foundation models for continuous-process manufacturing — pulp and paper, chemicals, and adjacent verticals. Industrial AI is bespoke by default: every plant, every product, every line needs its own model. To ship at our customers' pace we had to build a studio for authoring priors, composing architectures, training, and sharing trained models. PFN Studio is that internal studio, opened up. The platform you see here is the same one our team uses on production deployments.
Are you affiliated with Prior Labs or TabPFN?
No. PFN Studio is an independent project from ProfitOps Inc. Prior Labs (acquired by SAP in 2026) builds TabPFN, a separate tabular foundation model. We share the same research roots — Prior-Data Fitted Networks, introduced by Müller et al. at ICLR 2022 — but operate as separate companies and products. ProfitOps also ships its own model in the PFN family, TCPFN (Temporal Causal PFN), built and trained on the PFN Studio platform you see here.
Do I need labelled data?
No. PFN Studio trains on synthetic priors — Python code that generates data. The trained model then does in-context inference on your real data at runtime, without ever being shown a labelled example.
How is this different from Hugging Face?
Hugging Face hosts pre-trained models built by other people. PFN Studio is where you author the prior, train your own foundation model on it, and deploy. Different layer of the stack — HF gives you finished cake; we give you the oven.
What if my use case isn't in the marketplace?
Open the Designer and write your own prior in Python. Five built-in families to start from (regression / classification / time-series / Bayesian / causal), or start blank. The marketplace grows from there — we add new priors regularly and accept community contributions.
Is my data private?
Yes. Priors are synthetic — your real data is never used for training. At inference time data is sent only to your account's API endpoint, isolated per-organisation, and is never used to improve the platform.
What does pricing look like?
Free during early access — no card, no usage caps. Tiered pricing (Free / Pro / Team) goes live when we leave beta; we will publish the schedule before the first paid plan is enabled. No surprise bills.
Can I self-host or run on my own GPU?
The training subprocess is portable Python, so `pfnstudio run` works from any machine. Hosted training is the default and what we recommend; self-hosted compute (Modal / Vast / RunPod / your own cluster) is scaffolded and lands properly in v0.6 for teams with compliance constraints.
Your data deserves its own studio.
Free during early access. No credit card. No installs. We host the training.